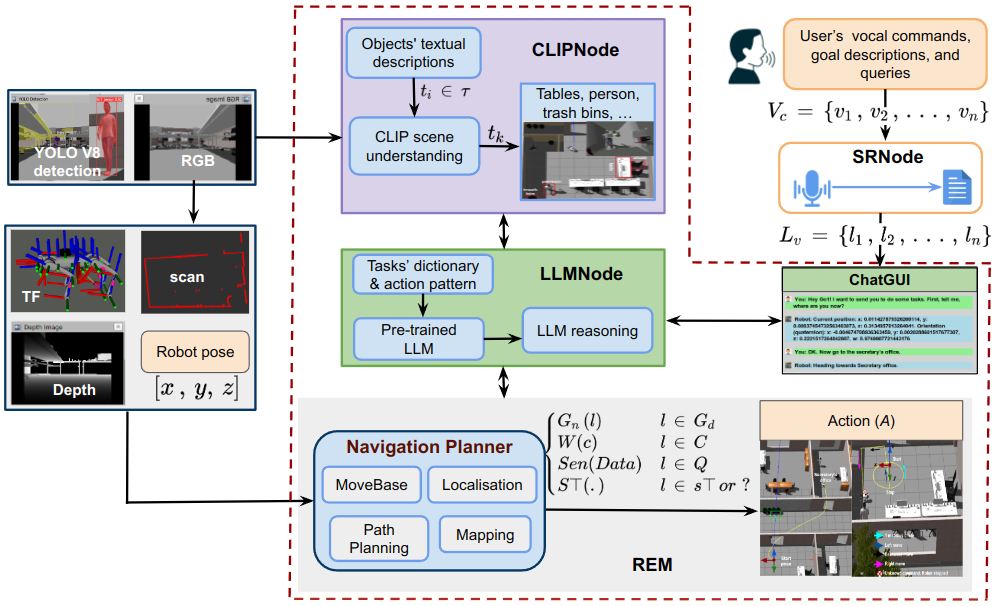
Quantitative Evaluation Results
Metrics
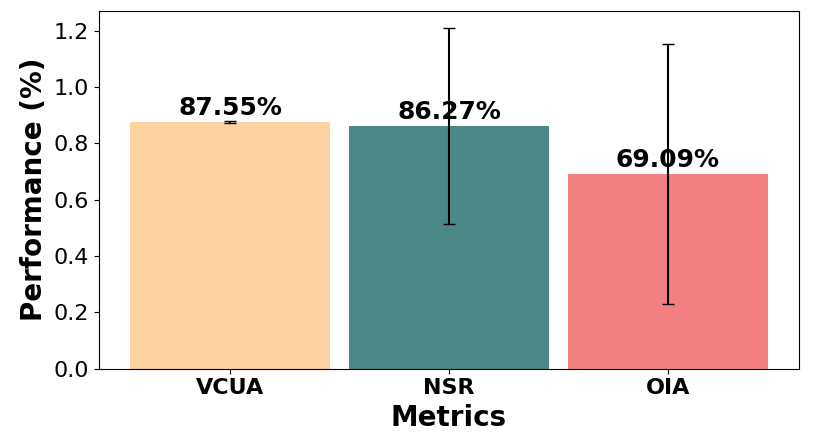
VCUA:
87.55% LLMNode prediction accuracy for several vocal commands based on the transcribed vocal instructions from the SRNode. < 3% confusion
NSR:
86.27% accuracy in the REM’s ability to abstract the high-level understanding from the LLMNode to the actual robot’s navigation actions.
OIA:
69.09% CLIPNode accuracy in identifying and localizing objects within the robot’s task environment.
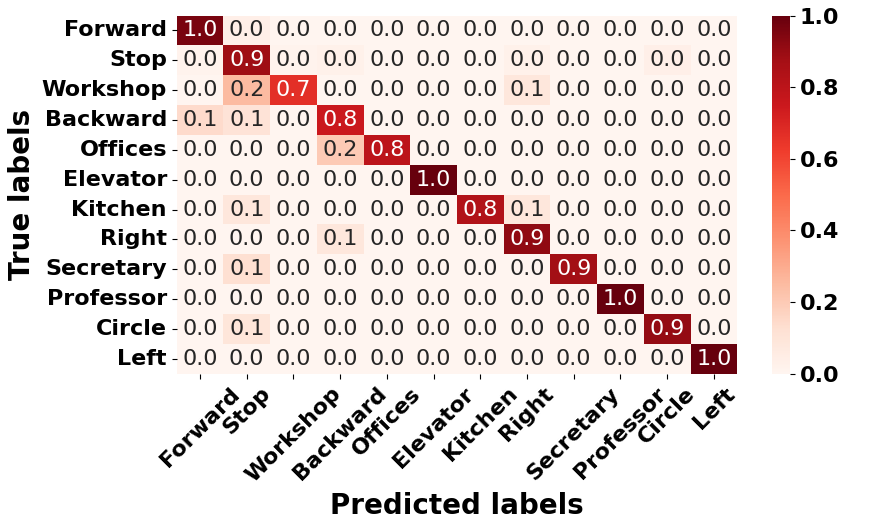
Confusion Matrix:
strong predictive accuracy for several vocal commands, e.g., vocal instructions completely in English sentences (phrase or clause).
struggles with some vocal commands, e.g., vocal instructions containing action descriptions specified in non-English words. "Workshop" and "Offices" contain the majority of the action patterns described with non-English words in the task dictionary.
Commands Sent and Received Time
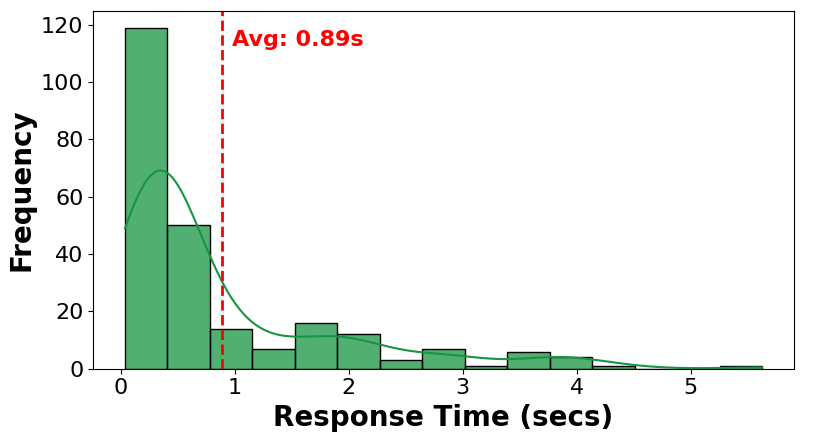
Robot's Average Response Time
ART:
on average, the robot takes less than a second from receiving a vocal chat command to initiating the robot's actual physical action, which suggests a relatively quick response time for our framework.